Vocabulary management
Tacsi is a tool for managing and refining vocabularies produced by natural language processing and text recognition.
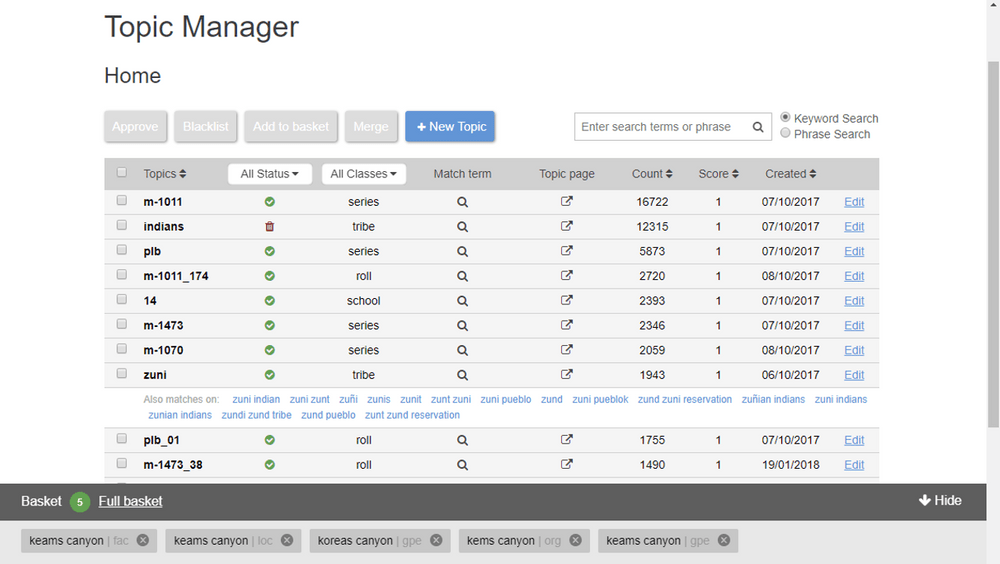
Tacsi is a tool for managing the vocabulary that emerges from a crowdsourcing project, and especially where some of the vocabulary has been generated from Named Entity Recognition, using text obtained through OCR of sometimes poor quality images.

In the Indigenous Digital Archive project, we identify entities in the text using a mixture of general purpose natural language processing tools and project-specific sources, such as gazetteers of place names and lists of tribes and schools. The general purpose entity extraction will identify terms as people, places, organisations, dates and so on, but due to OCR irregularities and poor source material, the first pass through the material can generate a poor quality vocabulary.

The process may also read the text perfectly but incorrectly classify the entity. For example, the term "Cliff Dwellings" appears several times and was identified as a person.
In the IDA project, we use the terms extracted to generate Generous Interfaces, but without any intervention, there can be a lot of noise in the identified topics.

Using Tacsi, project staff (and volunteers) can clean and manage the emerging vocabulary. Actions taken in Tacsi have two principal effects. They update the authorities for those terms, reclassifying and merging existing tags. They also feed back into the natural language processing module, so that already identified synonyms and OCR mistakes will be identified as the corrected term next time they are seen.
New terms can be added to the vocabulary directly. In the IDA case, the same vocabulary is available to users of the platform to tag content. This creates a virtuous circle of vocabulary improvement and usefulness, even when large parts of the vocabulary have emerged from machine processing.